Fault tolerance and high availability are two terms used in IT. Some professionals may have heard about them and those two technologies have been widely applied in business. In this article, the introduction of fault tolerance vs high availability will be clarified. For more details, you can see it on MiniTool Website.
Fault tolerance and high availability are both used as an emergency plan that can shorten downtime and keep your systems up and running when something fails in your devices. But they do have their differences that require some attention.
The first part will tell you what fault tolerance and high availability are and you can tell the difference between fault tolerance and high availability from their types and components.
Fault Tolerance
Fault tolerance is the ability of a system to operate normally in the event of the failure of one or more components, or the ability of software to detect and recover from errors in the software or hardware on which an application is running.
For example, in a dual-machine fault-tolerant system, when one machine has a problem, another machine can replace it to ensure the normal operation of the system. This was common in the early days when computer hardware was not particularly reliable.
Nowadays, fault tolerance is still an important approach for systems that do not allow errors.
High Availability
The term high availability is often used to describe a system that is specifically designed to reduce downtime while maintaining the high availability of its services.
In designing the usability of the system, the most important thing is to meet the needs of users. The failure of a system affects its availability metrics only when it causes services to fail sufficiently to affect the needs of system users. The sensitivity of users depends on the applications provided by the system.
Talking about high availability, it is necessary to touch on another term – high availability cluster.
High Availability Cluster
High availability clusters are groups of physical machines that act as a single system and provide continuous availability.
High availability clusters are used for mission-critical applications like databases, e-commerce websites, and transaction processing systems. They are typically used for load balancing, backup, and failover purposes.
Presenting their separate definitions may be less clarified to show the difference between fault tolerance and high availability. The next part is about an overall comparison between fault tolerance and high availability and you will have a better understanding of their functions.
Fault Tolerance vs High Availability
Working Principle
Although fault tolerance and high availability share the same purpose to maintain a normal function of the system, they run in different ways.
Fault tolerance:
Fault tolerance relies on specialized hardware to detect hardware failures and immediately switch to redundant hardware components.
Although this transformation is obviously seamless and provides uninterrupted service, it is costly in hardware costs and performance because redundant components are not processed.
More importantly, fault-tolerant models do not address software failures, which are by far the most common cause of downtime.
High availability:
High availability views availability as a set of replicated physical components, rather than as a set of system-wide shared resources that collaborate to guarantee essential services.
High availability combines software with industry-standard hardware to minimize downtime by quickly restoring essential services in the event of a system, component, or application failure. At the same time, the service is restored quickly, usually in less than a minute.
In a short, a fault-tolerant environment has no service interruption but a significantly higher cost, while a highly available environment has a minimum service interruption, which can also be regarded as the greatest difference.
Measurement Index
Fault tolerance:
You can measure fault tolerance by the following aspects:
- System reliability
- System availability
- System testability
For computers, the most important one is system availability, which means the rate of time over a year to ensure that the system does not fail.
High availability:
For high availability, it has a specific formula to test.
%Availability=(Total Elapsed Time-Sum of Inoperative Times)/ Total Elapsed Time
Elapsed Time=Operating Time + Downtime
Working Modes and Components
Fault tolerance:
There are three components of a fault-tolerance system.
1. Diversity
It provides multiple different implementations of the same specification and uses them like replicated systems to cope with errors in a specific implementation.
For example, when a system’s main electricity supply fails and no other electricity is available, fault tolerance can be sourced through diversity and provide electricity from sources.
2. Redundancy
It provides multiple identical instances of the same system and switches to one of the remaining instances in case of failure. It can be used to remove the single point of failure and be imposed at a system level. In other words, an entire alternate computer system is in place in case a failure occurs
3. Replication
It provides multiple identical instances of the same system or subsystem, directs tasks or requests to all of them in parallel, and chooses the correct result based on a quorum.
High availability:
There are three ways of high availability works.
1. Asymmetric Mode
The main machine is working, and the standby machine is in monitoring readiness; When the host is down, the standby host takes over all the work of the host.
After the host recovers, services are automatically or manually switched to the host based on user settings. Data consistency is ensured through the shared storage system.
2. Duplex Mode
The two hosts simultaneously run their own service work and monitor each other. When any host breaks down, the other host immediately takes over all its work to ensure real-time work. The key data of the application service system is stored in the shared storage system.
3. Cluster Working Mode
Multiple hosts work together to run one or more services and define one or more standby hosts for each service. When a host fails, the services running on it can be taken over by other hosts.
Level of Disruption
In this part, high availability will have a greater level of disruption than the fault-tolerance system.
During a crossover event when high availability systems move traffic from failing systems to healthy ones, several factors can take effect.
- Software monitoring for failure.
- The ability to identify the real failures and false positives.
- The event that triggers the crossover to a healthy system.
In this process, you may encounter a brief outage event. Compared to fault tolerance that supports a seamless transmission for the end-user, a brief outage can put high availability in an inferior position.
Fault tolerance can guarantee that the system and the information it contains are always online, which is a massive benefit for many organizations.
Infrastructure Requirements
High availability:
It requires each component of the system or infrastructure to be replicated to provide sufficient protection against outages and failures, resulting in redundant components.
The fault-tolerant system:
It requires a complex system. Fault-tolerant systems are extremely complex systems that process traffic while replicating information in real-time.
Mirroring information from a hardware and software perspective is difficult and time-consuming. In addition, many applications do not simultaneously process mirrored data and requests and also service the same requests for reading and writing information.
Pros and Cons
High availability:
Pros:
- Cost-saved – compared to fault tolerance, its lack of complexity increases ease of use and simplifies maintenance.
- Easily scalable – the system’s overall design is simplified.
- Load balanced – traffic is split over multiple environments, with the traffic consolidating in a failure.
Cons:
- Service disruption – just as we mentioned, high availability will have several seconds for downtime.
- Rare data loss – a high availability system can produce a data loss in some cases because it may cause a narrow gap of an outage, in which the more detrimental factor is data loss.
Fault tolerance:
Pros:
- Zero interruption – no interruption improves end-user reliability and provides a unique opportunity for the owner or operator to respond to any activity that could cause an interruption.
- No data loss – accompanied by the no service interruption, data integrity can be its greatest advantage.
Cons:
- System complexity – this complexity creates many opportunities for design failures that can cripple and prevent the system from working or provide the customer with the wrong information.
- High cost- because of such a complex architecture, fault-tolerant systems have numerous moving pieces that require much expense.
Why Are Fault Tolerance and High Availability Important?
The main benefit of both high availability and fault tolerance is the protection against hardware failure.
If a running instance in a highly available cluster fails because of a buggy application on it, the new instance of that workload that replaces it likely will also fail for the same reason.
In this way, fault tolerance can minimize or avoid the risk of systems becoming unavailable due to a component error.
There are multiple situations you can use them:
- You have to deal daily with critical application management.
- You manage a website with high traffic volumes.
- You can’t afford any downtime.
- Interruptions of service are your worst nightmare.
- A part of your job is about assuring high-performance.
- You simply want good, available service.
Whether fault tolerance or high availability, they both can take effect in your work and their efficacy is indelible.
Best Practices to Configure Fault Tolerance and High Availability
This part will give you a list of practices that can help achieve fault tolerance and high availability.
Prevent software failure – as we mentioned, high availability and fault tolerance are designed for hardware failure, not considering the software. You may need another plan to prevent software emergencies.

Consider the cost – the infrastructure costs of fault tolerance and high availability will increase. You need to think if the bill is worth the benefits.
Back up data – these two emergency plans cannot be regarded as a substitute for a backup plan. Data loss is a risk in either environment, due to issues such as data deletion or the failure of backup servers or application instances.
In this way, even if you have set up your emergency plan for maintaining the good functioning of the computer, you have to make your backup regularly.
Back up in Advance – MiniTool ShadowMaker
MiniTool ShadowMaker can offer you an excellent backup service and give you more options to make backup perfect.
MiniTool ShadowMaker TrialClick to Download100%Clean & Safe
You can download and install the program first and you will get a free trial version for 30 days.
Step 1: Open the MiniTool ShadowMaker and click Keep Trial on the top right corner.
Step 2: Click the Source section and in the pop-up window you can choose backup content. Here, MiniTool ShadowMaker provides you with more options, including the system, disk, partition, folder, and file. By default, the system has been set as the backup source already.
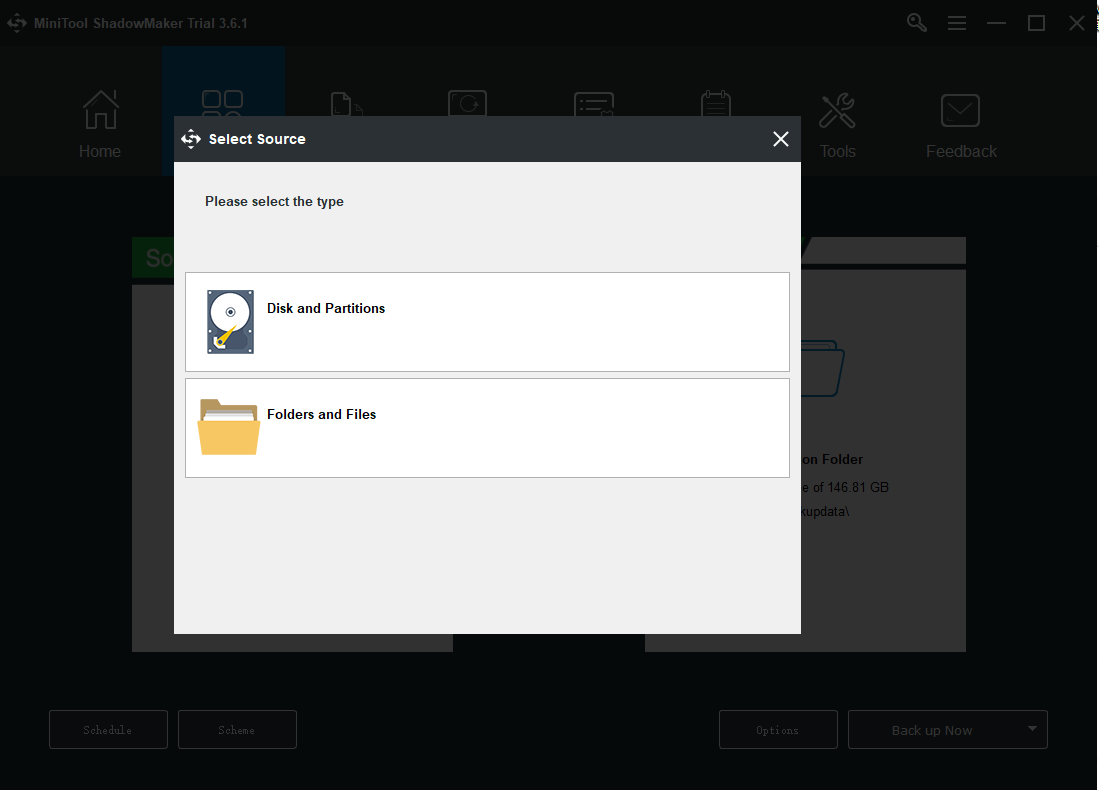
Step 3: Go to the Destination part where you can see four options containing the Administrator account folder, Libraries, Computer, and Shared. Then choose your destination path. And then click OK to save your changes.
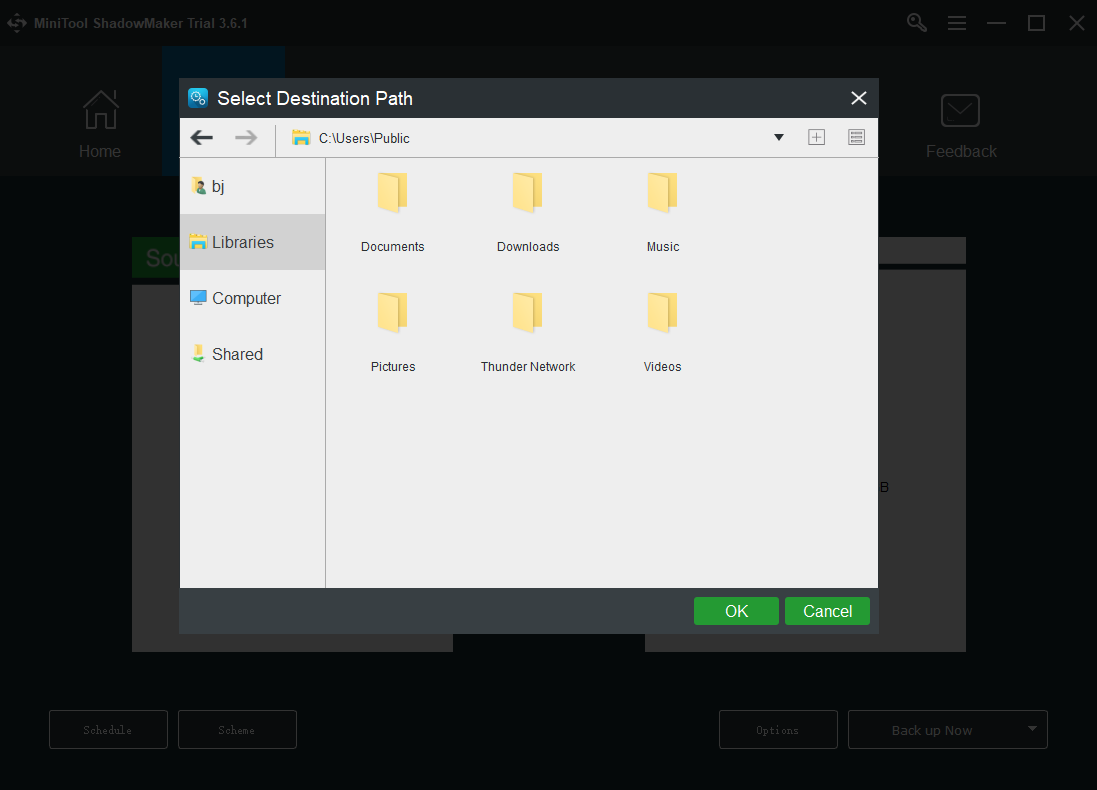
Step 4: Click the Back up Now option to start the process immediately or the Back up Later option to delay the backup. The delayed backup task is on the Manage page.
Bottom Line:
After reading this article about fault tolerance vs high availability, you’ve had your own opinion. If you are running a business, you can choose one of them as your emergency plan. Hope this article is useful for you.
If you have encountered any issues when using MiniTool ShadowMaker, you can leave a message in the following comment zone and we will reply as soon as possible. If you need any help when using MiniTool software, you may contact us via [email protected].
User Comments :